Can LLMs improve collective decision-making?
What research tells us
Abstract
When a group needs to make a decision in a team, workshop, or organization, we often expect the collective to perform better than its individual members. However, the arrival of language models (LLMs) in these contexts raises a simple question: does AI truly improve our decisions, or can it sometimes degrade them?
Based on a simple and reproducible collective intelligence experiment, this conference demonstrates how naive use of AI can lead to seemingly convincing but less reliable decisions in practice.
Drawing from recent research on collective intelligence and AI-assisted deliberation, we analyze cases where AI weakens or strengthens collective decision-making, and why these effects depend primarily on how it is integrated.
The conference concludes with a framework for thinking about AI as a facilitation tool rather than an authority, helping teams design more robust and transparent collective systems.
Format
Presentation followed by Q&A · Tech talk (45 min)
Target Audience
Data teams, decision-makers, tech enthusiasts. No specific technical prerequisites required.
Prerequisites
No specific technical prerequisites
Previously presented
- Decathlon: Facilitators community, Global Data team — February 2026
- Theodo: Internal tech talk — February 2026
- Data Days Lille 2026 — March 2026
Detailed content Reveals the talk's content

The starting promise
In 2016, Taiwan regulated Uber's arrival using Polis, a digital deliberation platform developed by the civic community g0v: thousands of citizens submitted proposals, voted, and the platform mapped convergence zones between parties with opposing interests. The debate forced Uber to take a public stance. A law was passed. It was the first time a technology structured a public decision at scale.
The question that follows: with LLMs capable of processing thousands of text-based opinions, can we go further: summarise, synthesise, aggregate to make better collective decisions, faster?
Why the naive approach fails: three levels

As an opening illustration
Replicating Galton's experiment (1907) with a jar of sweets, the talk shows how consulting an LLM before estimating introduces an anchoring effect that homogenises individual responses and dissolves the wisdom of crowds. This is just an initial intuition. The talk then focuses on decision-making tasks: collective decisions with no verifiable solution (organisational strategy, public policy), for which classical aggregation functions simply do not work.
Naively aggregating opinions via an LLM raises four structural problems. The context window limits the volume of opinions that can be ingested (300 to 1,500 pages depending on the model). Hallucinations make the summary potentially unfaithful to sources. The tendency to weight by frequency crushes brilliant but rare ideas. Finally, LLMs can be reproducibly positioned on standardised political axes; this bias can systematically favour certain positions in a synthesis.
Counter-measures exist:
- Context window → hierarchical summaries by topic
- Hallucinations → grounded generation with citations (RAG), verifiable by a human
- Minority opinions → LLM-as-a-Judge: a third-party model checks that each individual opinion is reflected in the final summary
- Bias → full model openness (weights, data, procedures). E.g.: Aperture (EPFL / ETH Zürich)

At a more fundamental level: even perfect aggregation is not enough. The example of 12 Angry Men (Lumet, 1957) is central: aggregating the jurors' initial opinions (11 votes for guilty) would have produced the wrong verdict. It is deliberation, the exchange of information and the confrontation of lived experiences, that collectively reverses the judgement. Deliberation is not a luxury: it is a condition for quality.
But deliberation itself is subject to well-documented biases. When a group is left to deliberate freely, four mechanisms degrade decision quality: the hidden profiles effect, where participants tend to discuss only information already shared and fail to reveal potentially key private information; the cognitive homogeneity trap, where participant similarity reduces the diversity of analytical perspectives; unequal speaking time, where the most talkative individuals drown out the opinions of others; and finally natural polarisation, where debates push positions to extremes rather than bringing them closer together. It is precisely to mitigate these effects that a structured protocol is needed, and that AI can play a useful role, provided it is integrated at each stage as a tool, not as a decision-maker.
- Galton, F. Vox Populi. Nature, vol. 75, 1907. doi: 10.1038/075450a0
- Santurkar, S. et al. Whose Opinions Do Language Models Reflect? ArXiv, 2023.
- Feng, S. et al. From Pretraining Data to Language Models to Downstream Tasks. arXiv, 2023. doi: 10.48550/ARXIV.2305.08283
- Small, C.T. et al. Opportunities and Risks of LLMs for Scalable Deliberation with Polis. arXiv, 2023. doi: 10.48550/ARXIV.2306.11932
- Lu, L. et al. Twenty-five years of hidden profiles in group decision making. Pers Soc Psychol Rev, 2012. doi: 10.1177/1088868311417243
- Kerr, N.L. & Tindale, R.S. Group performance and decision making. Annu Rev Psychol, 2004. doi: 10.1146/annurev.psych.55.090902.142009
What recent research proposes
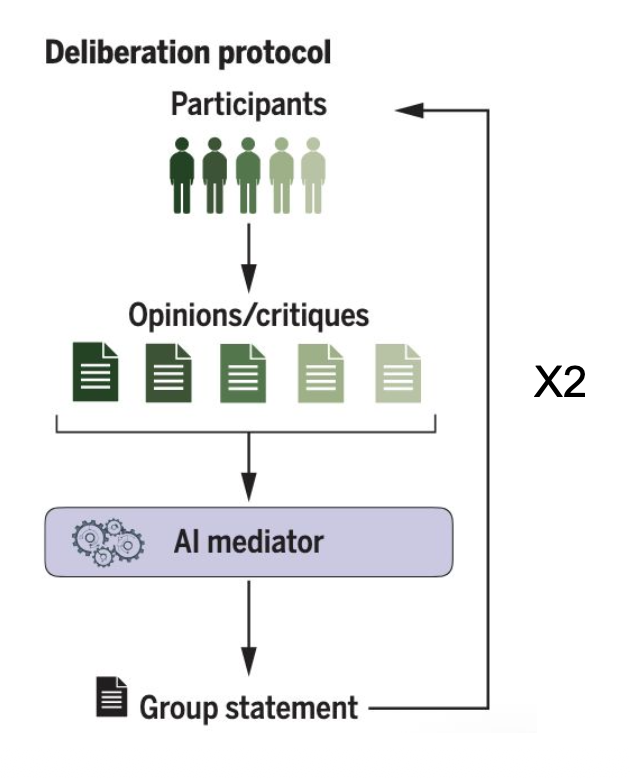
Tessler et al. (2024, Google DeepMind, published in Science): a specially trained LLM aggregates individual opinions and generates a group statement, a candidate common position. This statement is submitted to participants who critique it. The LLM integrates the critiques and produces afinal group statement. Groups converge faster than in classical deliberation with a moderator, and participants on average prefer this assisted mode. The question of desirability is explicitly raised by the authors themselves.
Plurals (Ashkinaze et al., 2025): LLM agents personify social profiles sampled from a target population. These agents deliberate among themselves, moderated by a moderator-agent, and produce arguments. On the example of solar panels in private gardens, the generated arguments are deemed acceptable by the communities concerned. Same caveat: substituting agents for human deliberators raises the question of the process's legitimacy.
Both experiments raise the same underlying question: why do we make decisions collectively? It is not just a matter of efficiency; it is first and foremost a question of values. Lazar & Manuali (2024) propose a framework of six values:
Instrumental · efficiency
Collective intelligence Opinion transformation Conciliation
Non-instrumental · legitimacy
Equality of voice Intrinsic participation Perceived legitimacy
An AI usage that optimises efficiency at the expense of participation or perceived legitimacy is not necessarily desirable, even if it produces technically superior results.
- Tessler, M.H. et al. AI Can Help Humans Find Common Ground in Democratic Deliberation. Science 386, n° 6719, 2024. doi: 10.1126/science.adq2852
- Ashkinaze, J. et al. Plurals: A System for Guiding LLMs via Simulated Social Ensembles. CHI, 2025. doi: 10.1145/3706598.3713675
- Lazar, S. & Manuali, L. Can LLMs advance democratic values? arXiv, 2024. doi: 10.48550/ARXIV.2410.08418
The concrete proposal
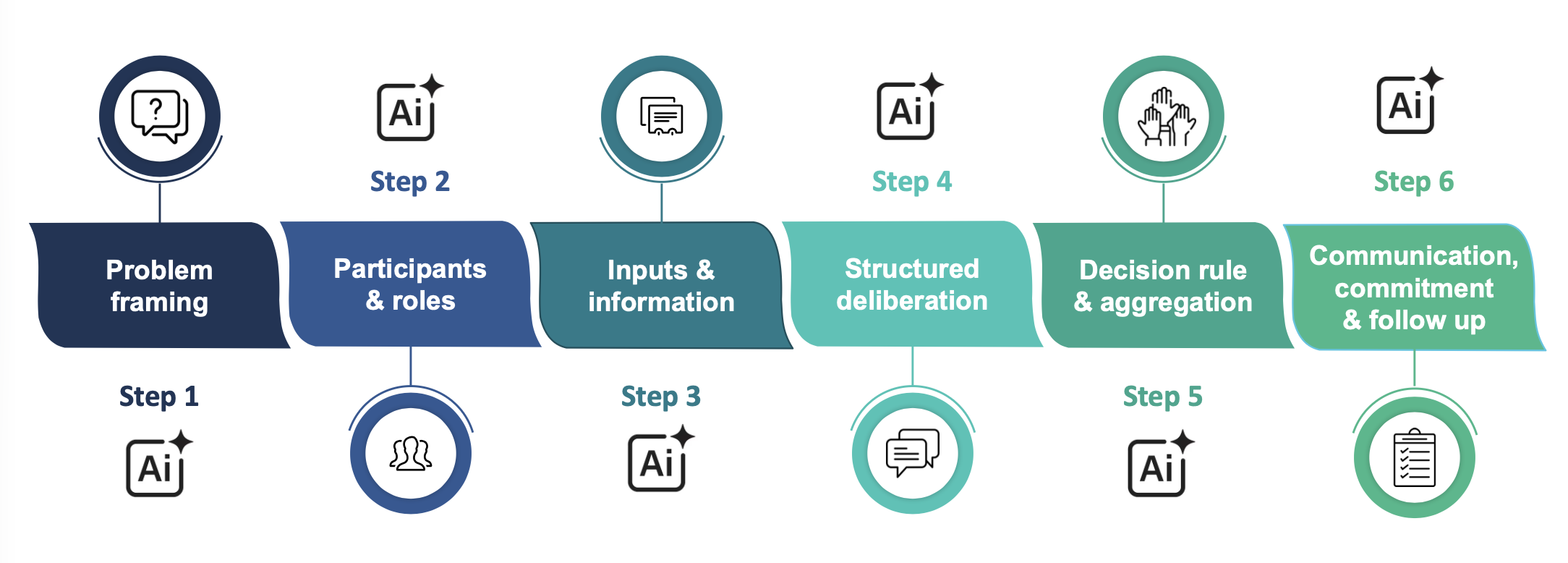
Rather than substituting AI for the deliberative process, the talk proposes inserting it at each stage of a 6-step structured protocol: debiasing the problem framing (1), supporting representative participant selection (2), individual sparring partner before the collective debate, where each participant tests and refines their arguments before entering the discussion (3), facilitating speaking time and detecting polarisation (4), aggregation (5), communication and follow-up (6).
AI as a facilitation tool at each node of the process, not as a shortcut to a final synthesis. The quality of integration matters more than the sophistication of the model.